Computational Analysis | Back to Potential Authors
What is NLP? | Methodology | Findings & Charts | Conclusion
The introduction of computational analysis to the scholarly field of the humanities has transformed how researchers study literature, history, and culture, but it remains a point of contention. Traditional humanities research emphasizes close reading, interpretation, and qualitative analysis; methods that have long been central to the field. However, computational tools like text mining, Natural Language Processing (NLP), and stylometry offer a new approach, allowing scholars to analyze vast amounts of data quickly and at a scale that would be impossible through traditional methods.
One key advantage of computational analysis is its ability to detect patterns, trends, and anomalies across large bodies of texts. For example, these tools can identify shifts in language use, stylistic elements, or cultural themes over time, which may not be noticeable through close reading alone. This opens up new possibilities for cross-comparative studies between different periods, genres, and authors, enriching the scope of humanities research. Moreover, computational methods facilitate large-scale projects by enabling scholars to analyze entire digital archives, making it easier to uncover hidden connections and broader insights.
However, the rise of digital humanities has sparked debates among scholars. Traditionalists argue that close reading and human interpretation remain irreplaceable, fearing that computational analysis may oversimplify complex texts. Meanwhile, digital humanities scholars advocate for the integration of both approaches, suggesting that modern tools can complement, rather than replace, traditional methods. Despite the contention, computational analysis is gaining traction, offering a powerful way to expand the depth and breadth of humanities research.
The debate between traditional and computational methods in the humanities may soon become a moot point due to the ubiquitous presence of computers, smartphones, and digital tools in the lives of modern students and researchers. Today's students, raised in a digital world, are growing increasingly more accustomed to using technology for research, writing, and communication. This familiarity with digital platforms makes it easier to integrate computational methods into their academic work. As a result, many emerging scholars are not only comfortable with but expect to use modern tools like text mining software, digital archives, and data visualization programs in their research.
This generational shift means that the divide between "old" and "new" methods will likely diminish over time as digital approaches become a standard part of humanities education. Rather than replacing traditional methods, computational tools are more likely to be seen as essential supplements that can deepen textual analysis and broaden research possibilities. In this sense, the future of humanities scholarship may lie in a blended approach, where the close reading of individual texts and the large-scale analysis of patterns coexist, allowing scholars to take advantage of both traditional and digital methods in their pursuit of knowledge.
What is NLP?
Natural Language Processing, or NLP, can sound intimidating, but in practice it’s essentially about teaching computers to interact with human language—understanding, analyzing, and even generating it. The process starts with selecting the texts that you want to work with. In today’s world, many of these texts are "born-digital," meaning they were originally created in digital format rather than being scanned or digitized from physical sources. Born-digital texts can include emails, social media posts, e-books, and websites. These documents are already in machine-readable format, which makes them easier to process compared to older texts that need to be scanned and converted into digital format.
For older, printed, or handwritten texts, a process called Optical Character Recognition (OCR) is typically used. OCR converts scanned images of printed text into machine-readable text. This process, however, isn’t perfect and may introduce errors, especially if the text is old, damaged, or formatted in an unusual way. In the case of handwritten manuscripts, a more specialized process called Handwritten Text Recognition (HTR) is employed, which is designed to recognize and convert handwriting into text. While born-digital content has made NLP work much more straightforward, these processes of OCR and HTR remain essential for working with historical documents and manuscripts.
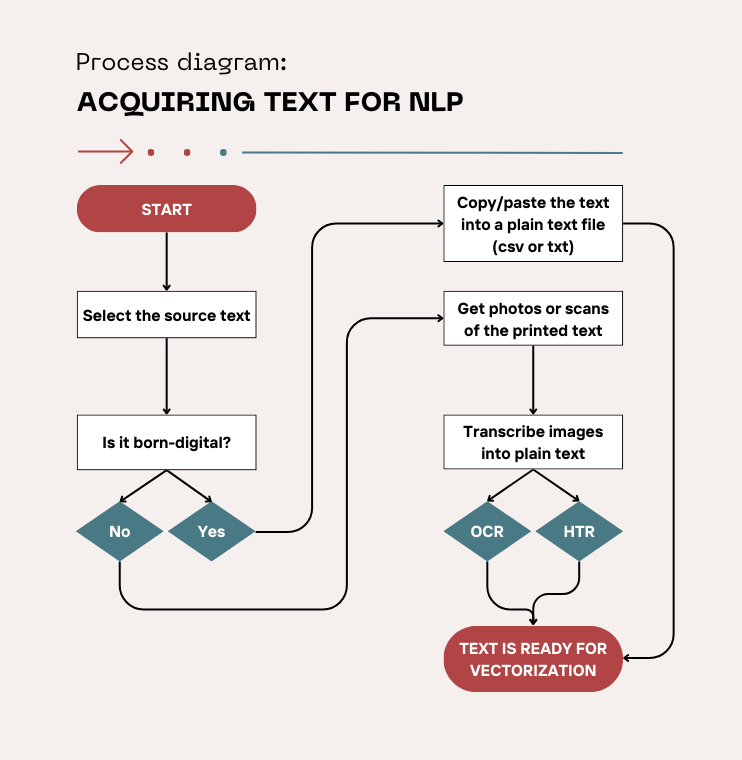
(Flowchart created in Canva.)
Once the text is available, ideally as a simple TXT or CSV file, the next step is to transform the text into something a machine can understand, because words and letters are meaningless to a computer that only really understands numbers. Transforming the text in this way is referred to as text vectorization; it transforms the text into numerical representations so that it can be analyzed by machine learning models or algorithms. The result turns the text into a dataset that is now ready to work with.
One common method is to represent each word as a unique number or a set of coordinates in a "vector space." Another is the "Bag of Words" approach, where the frequency of words is used to build a dataset. More advanced approaches like word embeddings can capture semantic relationships between words by placing them in a vector space where similar words are closer together.
However, before jumping into the analysis, it’s important to clean the data. Data cleaning in NLP involves removing irrelevant or potentially confusing information that could skew the results. The ultimate goal of data cleaning and text vectorization is to prepare the text for computational analysis, of which there are many methods and algorithms.
In my case, for authorship attribution—determining who wrote a particular text—common techniques include analyzing word frequencies, punctuation patterns, or sentence structures. Stylometric techniques, like Kilgariff’s Chi-Squared method or John Burrows’ Delta method, are often used in such cases to measure stylistic similarities or differences between texts. Machine learning models might be trained to recognize patterns in the writing, enabling more sophisticated and nuanced analysis. However, the downside of machine learning models is that they are very data hungry and only function well when there is a vast amount of text to work from.
After preparing the text and choosing the appropriate algorithms, the final step is to actually run the analysis. This could involve training machine learning models, comparing different texts, or calculating statistical measures of word usage. The results could reveal hidden patterns, differences between authors, or even shifts in language over time. With this combination of linguistic processing, data cleaning, and computational analysis, NLP opens up a wide range of possibilities for understanding and interpreting texts in new ways.
Methodology
The process of authorship attribution began with selecting and acquiring the texts I planned to use. I started with identifying early versions of the Histoire de la Marquise-Marquis de Banneville. I gathered these from the rare book collections at the Bibliothèque nationale de France (BnF) where first and second editions are available as digital copies, and the 1723 edition of the Histoire is available in print form; I also collected texts from the three potential authors. Once acquired, the texts were digitized and preprocessed to form a dataset suitable for computational analysis. “Preprocessing” in this case means data cleaning.
This included removing special characters, punctuation, or non-standard letters like accented characters. In some cases, all letters might be converted to lowercase to ensure uniformity. When working with older texts that were digitized through OCR, this process also involved correcting transcription errors that could have been introduced during scanning. The goal was to make sure the text is as clean and uniform as possible.
Another key part of the data cleaning was deciding whether or not to remove stop words. Stop words are common words in any language like "the," "is," "and," or "of" that do not carry specific meaning on their own but are necessary for constructing sentences. In some NLP applications, like topic modeling, these stop words might be removed to focus on content-heavy words. In contrast, to some analysts the stop words might carry subtle but important clues about a writer's style and therefore may be left in the dataset.
The next step involved creating a dataset from these texts, using NLP techniques in Python. Python is a versatile and accessible programming language known for its efficient high-level data structures and straightforward approach to object-oriented programming. Designed to be easy to learn, it has become widely popular across various fields, from web development to data analysis. (Its creator, Guido van Rossum, named the language after the BBC comedy show Monty Python's Flying Circus, adding an element of humor to the language’s origins.) Python is also classified as FLOSS (Free/Libre and Open Source Software), meaning its source code is freely available for anyone to use, modify, and distribute.
This open-source philosophy has encouraged a vast community of developers to contribute additional tools and libraries, enhancing Python’s capabilities. Many libraries are made available on platforms like GitHub, enabling others to benefit from and expand on existing resources. In the context of Python coding, a GitHub library is a collection of reusable code, tools, and resources shared on GitHub, often organized as a repository. It typically includes Python modules, functions, and classes designed to perform specific tasks or add functionalities; everything from data analysis to machine learning). Developers can integrate these libraries into their projects by cloning or downloading the repository or installing it. Libraries on GitHub often come with documentation, examples, and licensing information to help users understand and use the code effectively.
The collaborative nature of Python has produced a variety of specialized tools, including Fast Stylometry, which is just one example of a library resource that can be used for handling complex analyses. I’ll be incorporating Fast Stylometry into my project in order to utilize John Burrow’s Delta method. It’s a commonly used statistical method for authorship attribution in which the algorithm calculates the "delta" or difference between the frequencies of common words (or other stylistic markers) in an unknown text and in samples of known authors’ works. By using standardized differences, Burrows's Delta highlights the distinctiveness of an author's style, helping to match a text to its most similar known author profile.
ACQUIRING TEXT
Using resources like WorldCat.org, I located editions of the Histoire and identified comparison texts from the same historical period. When selecting comparison texts for author attribution, I knew it was best to choose works that were similar in time period, genre, and style to the text in question. This ensured a fair basis for comparison, as patterns of language use, themes, and stylistic choices are more likely to align.
The goal was to find works with similar themes, subject matter, or time period to compare linguistic styles. These included Charles Perrault’s Mother Goose Tales, which are contemporaneous fairy tales, as well as the particular edition of Sleeping Beauty that was published in the Mercure galant in the same year as the Histoire’s second edition. I also selected Madame L'Héritier Oeuvres Meslées, particularly including Marmoisan, for its thematic similarity of cross-dressing, and the Memoirs of the Abbot de Choisy Dressed as a Woman by the abbé de Choisy, given its relevance to gender fluidity, as well as a volume of his Memoires Pour Servir A L'Histoire de Louis XIV because its description of the royal court reflects experiences had by the Histoire’s main character.
To obtain these texts, I navigated the Gallica website of the Bibliothèque nationale de France (BnF) for digital versions and used a scan tent to photograph print-only editions, such as the 1723 third edition of the Histoire, as well as getting photographs of the microfiche copy of the 1928 La Centaine Histoire reprint. Some of the comparison texts I was able to find online via Wikisource and the Internet Archive.
MULTIPLE EDITIONS OF THE HISTOIRE
At the beginning of my project, I acquired the text of the Histoire de la Marquise-Marquis de Banneville from Sorbonne University’s Mercure galant project created by their Observatoire de la vie littéraire department (licensed under creative commons CC BY-NC-ND 3.0 FR). Their collection covered both the 1695 first edition of the Histoire as well as the second edition that was split across two months in 1696. However, I eventually discovered that whatever transcription process the Sorbonne used, it resulted in pages of the story missing from the final transcription in both editions. To fill the gap, I sought out the versions of the Histoire on Gallica, the BnF’s digital arm, in order to acquire PDF copies of the Mercure galant’s relevant publications. From there I split out the relevant pages. In order to validate the Sorbonne’s transcription, I did a side-by-side comparison of the magazine’s images and the transcription and manually typed in the missing sections when necessary.
(Screenshots of Gallica’s digital interface.)
The third edition of the Histoire was a standalone text that was never digitized. As far as I’m aware it was never reprinted either. I consider it a valuable addition to the dataset because it has two additional scenes. It will be interesting to see how the development of the story over time might impact the results.

(Personal photo taken using a BnF ScanTent.)
Using a scan tent at the BnF in Paris proved invaluable for photographing rare books, especially those not available in digital form. The scan tent allowed for high-quality, consistent lighting, which is essential for capturing detailed images of delicate, old texts without causing damage. This setup ensured that each page was evenly lit and free from glare or shadows, which can often obscure important details in rare manuscripts. The carefully controlled environment also minimized handling of the fragile books, preserving their condition. These high-resolution images were crucial for running OCR later, as clear and well-lit photos lead to better accuracy in text recognition.

(Personal photo of a BnF ScanTent.)
In addition to the 1723 edition, I also took photographs of the microfiche version of the 1928 La Centaine reprint of the Histoire. Ultimately, I decided not to use this text as it proved to be an identical reprint of the first edition, but by checking the microfiche I was able to verify that it was a reprint as well as establishing the editor’s note regarding the belief that the Histoire was a collaborative attempt between Charles Perrault and the abbé de Choisy.

(Personal photo of a BnF microfiche station displaying a Histoire title page.)
CHARLES PERRAULT TEXTS FOR COMPARISON
I began by selecting Charles Perrault’s Les Contes de ma mère l'Oye (Mother Goose Tales) for comparison. I chose the first edition, published in 1697 under the title Histoires ou Contes du temps passé, because it appeared only a year after the second edition of the Histoire de la Marquise-Marquis de Banneville. This proximity in time made the text an ideal candidate for comparison, as it minimized the influence of later editing and refinement that could obscure Perrault’s earlier writing style. By focusing on this edition, my goal was to capture the author’s most authentic linguistic patterns of this time period.
The text was sourced from French Wikimedia, which has a complete transcription of this edition. The stories included are La Belle au bois dormant (Sleeping Beauty), Petit Chaperon rouge (Red Riding Hood), La Barbe bleüe (Bluebeard), Le Maistre Chat, ou le Chat botté (Puss in Boots), Les Fées (The Fairy), Cendrillon, ou la Petite Pantoufle de verre (Cinderella), Riquet à la houppe (Riquet with the Tuft), and Le Petit Poucet (Tom Thumb).
For curiosity’s sake I also be included in the dataset the version of La Belle au bois dormant that was published in the Mercure galant in February 1696. This is the one with the editor’s note that it was written by the same person who wrote the Histoire—it will be interesting to see what the comparison results will be.
(Screenshot of Wikimedia “Contes ou Histoires du temps passé - Les Contes de ma Mère l'Oye.”)
ABBE DE CHOISY TEXTS FOR COMPARISON
In addition to Perrault, I selected texts by the abbé de Choisy for comparison, even though he did not write traditional fairy tales. Choisy’s memoirs, which chronicle his experiences within the French court, interactions with the nobility and time spent dressed as a woman, contain content similar to that of the Histoire de la Marquise-Marquis de Banneville. Choisy’s memoires were first published in a partial collection as Mémoires pour servir à l'histoire de Louis XIV in 1727, only three years after he died. A more complete collection, serving as a sequel, was first published in 1736 as Mémoires de Madame la comtesse des Barres. This second collection is the one that describes Choisy’s upbringing and habits of crossdressing; it was reprinted as Aventures de l’abbé de Choisy habillé en femme in 1862.
I was able to source an already-digitized copy of Aventures from Project Gutenberg, though this edition was from 1920. To ensure accuracy, I compared this version to the oldest copy available on Gallica. After a detailed comparison, I verified that the content had not been modified, with the only difference being the sequence of the journal entries. Since sequence order would not affect the types of analysis I intended to perform, I concluded that the 1920 edition was acceptable for my purposes.
Additionally, I also included his Mémoires pour servir à l'histoire de Louis XIV that has similar content to the Histoire and was published closer in date to it, which I sourced an early edition from the Internet Archive. I also found a copy of his Journal du voyage de Siam from 1687, because Choisy’s memoirs lack specific dates, and I wanted to secure a text that was closer to the first and second editions of the Histoire. The inclusion of both memoirs and the journal established linguistic and thematic baselines that will support a comprehensive analysis by situating Choisy’s works within the social and literary context of late Seventeenth-century France.
(Screenshot of the Internet Archive’s digital interface.)
The text for the Mémoires pour servir à l'histoire de Louis XIV was originally drawn from the Internet Archive, which in turn got its text from Google OCR. I found this OCR had resulted in many errors, likely due to Google’s algorithms having been training on more recent printing samples and therefore struggling with the antique formatting and lettering of the Seventeenth-century. I would have to seek an alternative method of acquiring the text. (See the Transcription section for more).
MADAME L'HERITIER TEXTS FOR COMPARISON
Another key work in my authorship attribution study that I chose was Œuvres meslées, published in 1696 by Madame L’Héritier, the niece of Charles Perrault. Like Perrault, Madame L’Héritier produced works within the genre of fairy tales, making her collection an ideal comparison for the Histoire de la Marquise-Marquis de Banneville. The collection’s long title—Œuvres meslées : contenant L’innocente tromperie, L’avare puny, Les enchantemens de l’éloquence, Les avantures de Finette : nouvelles et autres ouvrages en vers et en prose—reflects the diversity of her works, which blend verse, prose, and short stories.
I have a particular interest in the collection of L’innocente tromperie (The Innocent Deception). Mentioned earlier, that is the story of Marmoisan, a tale featuring themes of gender disguise and fluidity. This genderqueer element aligned with the themes found in Histoire de la Marquise-Marquis de Banneville. I sourced a first edition digital copy of this work from Gallica and was able to download a PDF to create a transcription.
(A screenshot of Gallica’s copy of Œuvres meslées.)
Trascription: Traskribus and Tesseract
Much of the text I intended for the analysis dataset was able to be acquired digitally, because previous scholars had already transcribed the works. However, for the remaining works that had not yet been transcribed, or at least not accessible online, I used PDFs converted to PNG images as well as my own digital photos to create machine-readable texts. Working with Seventeenth-century texts, which often feature ornate typefaces, special characters, and non-standardized spelling, presented some challenges in digital transcription.
For this transcription process, I employed both Transkribus and Tesseract OCR. Transkribus is an advanced transcription and OCR platform that supports scholars in transforming historical documents into searchable and editable formats. It uses Optical Character Recognition (OCR) for printed text and Handwritten Text Recognition (HTR) for manuscript sources. In Transkribus, users can also train custom models tailored to specific fonts or handwriting styles, increasing transcription accuracy significantly, especially for complex or unique historical typefaces. For this project, I relied on Transkribus’s “Print M1” model, which offers a Character Error Rate (CER) of 2.20%, and is meant for multiple languages, including French. The fact that Transkribus has a user interface, rather than requiring you to work directly with code, and automated text region selection and recognition makes it more accessible to a lot of scholars.
Transkribus, in particular, was my initial tool, given my familiarity with it from an internship with the Paris Bible Project in 2023, where I learned how to leverage its capabilities for historical texts. Of the texts that I needed for my dataset, I used Transkribus on L’Héritier’s Œuvres meslées, and extracted Marmoisan from that collection. I also employed Transkribus towards Choisy’s Journal du voyage de Siam.
(Screenshot of the Transkribus interface.)
As I progressed through the course of my master’s degree and a second internship, this one with the University of Ghent and their Center for Digital Humanities, I gained more familiarity with using Python. Once I acquired the photos of the Histoire’s third edition using the ScanTent at the BnF, I decided to take the opportunity to use a Python notebook from the University of Ghent’s Centre for Digital Humanities. It was created by Bas Vercruysse and utilizes Tesseract OCR, which is an open-source optical character recognition (OCR) engine originally developed by HP and now maintained by Google. Like Transkribus, it converts images of text—like scanned documents, photos, or PDFs, etc—into machine-readable text using advanced algorithms to recognize characters and words in multiple languages. While Transkribus offers the ability to fine-tune transcription models and includes numerous built-in options, I opted to use Tesseract for the Python practice and found Tesseract sufficiently accurate when using good quality photos of printed text.
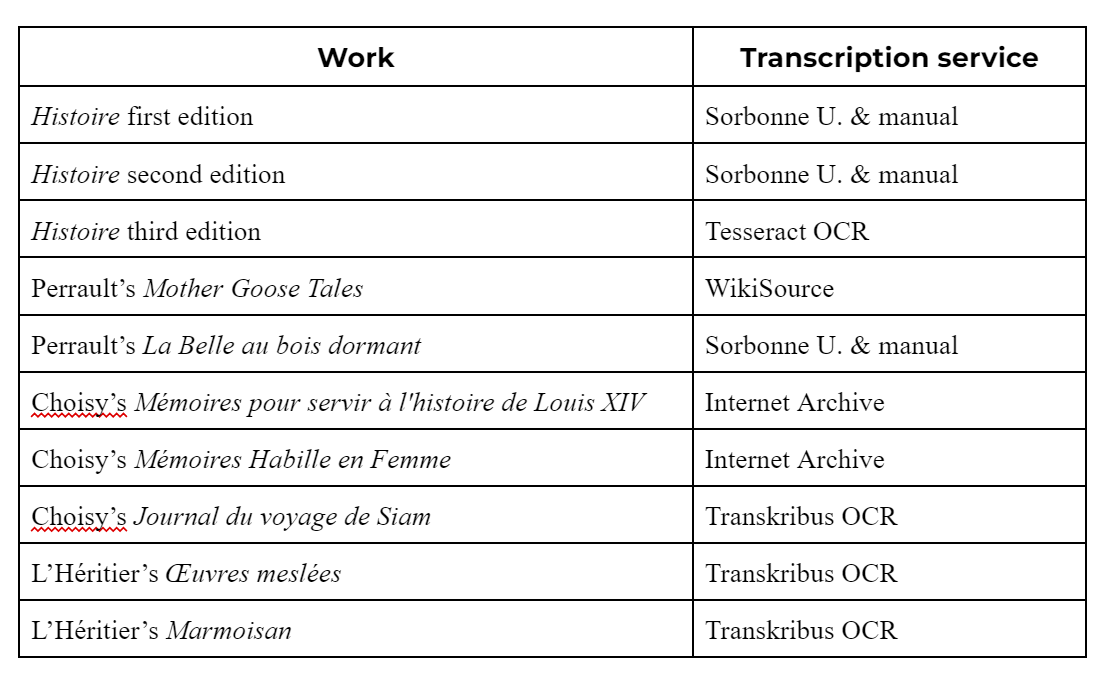
(Table 1. Works included with the type of transcription used.)
Creating the Notebook
The Python notebook I created for this project draws upon a variety of resources to support the data processing and analysis tasks involved. I chose Google Colab over Jupyter or Anaconda, two popular local development environments for Python, because Colab provides data integration with Google Drive, which simplifies accessing and storing data. My initial exposure to using Colab came from the Center for Digital Humanities (CDH) at UGhent, where I also learned methods for loading a corpus into the Colab environment.
For data cleaning, including the removal of stop words and punctuation using NLTK in Python, I adapted techniques shared by Geeks for Geeks, while refining portions of the code with guidance from the Programming Historian. For stylometric analysis, specifically calculating Burrows’s Delta, I followed a tutorial by Thomas Wood at Fast Data Science, which offered a clear, practical approach to authorship attribution. Each of these sources contributed significantly to the notebook’s development, reflecting the collaborative knowledge shared within the digital humanities and data science communities.
First I installed the library:
The “pip install” command is a simple way to download and install Python packages from the Python Package Index (PyPI) directly into the user’s development environment. So when I used “pip install [package_name]”, it not only installed the specified package but also checked for any dependencies that package requires, ensuring all necessary components are downloaded and compatible. This helped prevent issues with missing or mismatched dependencies, making it easy to add complex libraries and their requirements to my project with a single command. Then I started downloading the functions that will be needed later:
In Python, “import” is a keyword used to bring in external modules or libraries into a script, allowing access to pre-written functions, classes, and variables without having to code them from scratch. For example, using “import nltk” gets me access to the Natural Language Toolkit (NLTK), which is one of the largest Python libraries for performing various Natural Language Processing tasks. In my case I also import specific parts of a module (“from nltk.corpus import stopwords”) to access only the features needed, making the code more efficient and modular.
Lastly, I established the notebook’s connection to Google Drive and the files stored there:
from google.colab import drive
drive.mount('/content/drive/')
And the dataset in Google Drive looks like this:
In Fast Stylometry, the file naming convention is designed to help the code easily identify and separate the author name from the title of each document, which is important for accurate authorship attribution and analysis. Specifically, filenames should use “-” as a separator between the author’s name and the document title. This format ensures consistency in how the files are referenced, parsed, and annotated in the code, making it straightforward to extract the author information and title programmatically. For instance, a file named “data/train/perrault_-_mothergoose.txt” would allow the code to recognize “perrault” as the author and “mothergoose” as the title. This structured approach simplifies the management and retrieval of metadata across the dataset, supporting tasks like cross-referencing authors and analyzing stylistic differences between works.
Data Preprocessing
In the data preprocessing stage, I loaded the training texts—those with known authors for comparison. To preserve the original dataset during preprocessing, I renamed it with an “=” symbol, such as “file = train_corpus,” which created a copy of the data. This ensured that any modifications or cleaning steps affected only the duplicate and not the original dataset. This approach safeguards the integrity of the initial dataset, allowing me to reprocess if needed without having to reload the data.
The next step was removing stop words. As a reminder, stop words are a list of common words (e.g., "the," "is," "at") that are typically filtered out to focus on more meaningful vocabulary for authorship attribution. The NLTK library has a variety of languages available in order to select stop words; currently they are Arabic, Danish, Dutch, English, Finnish, French, German, Hungarian, Italian, Norwegian, Portuguese, Romanian, Russian, Spanish and Swedish.
Below are French stopwords available in NLTK:
The Fast Stylometry library was designed with only English texts in mind, which was why I needed the addition of the NLTK. You can see the code I used below, and note that any line with a preceding # is meant to be commentary rather than a command.
The last bit of code above is intended to rename the cleaned training data to a designation that aligns with the naming conventions used in the Fast Stylometry library. By doing this at this stage, I avoided having to make multiple adjustments across various blocks of code later on, thus streamlining the overall coding process and minimizing potential errors.
The following code snippet is also derived from the Fast Stylometry framework, and it performs a set of tasks similar to the more complicated code block above, but this time for English text. This demonstrates how an optimized function can efficiently handle complex operations based on a single command, showcasing the power of abstraction in programming. Such functions not only simplify the code but also enhance readability and maintainability, allowing for quicker adaptations when working with different languages or datasets.
Next it was time to repeat the same process to the testing data; in this case the three different editions of the Histoire.
Like the training corpus, you can see that I also used the tokenize function (visible immediately above as “tokenise_remove_pronouns_en”) even though it was designed for English and not for French. Despite the redundancy of tokenizing twice—once in the primary data cleaning code and then again here—this choice was necessary due to persistent errors that would arise when attempting to continue through the notebook without it. Each attempt to proceed without reapplying tokenization resulted in errors, disrupting the workflow. Therefore, ensuring that the notebook continued running smoothly took precedence, even if it meant tokenizing twice. Ultimately, since the English-specific elements like the pronoun removal in “tokenise_remove_pronouns_en” does not interfere with French-language texts, this workaround did not negatively impact the French corpus in any way.
What tokenizing does is to transform the text into something a machine can understand—strictly speaking, words and letters are meaningless to a computer that only really understands numbers. This transformation of text data into numerical form is referred to as text vectorization, a process that allows machines to treat words and phrases in ways that are computationally meaningful. Tokenization specifically involves breaking down text into manageable, meaningful units—typically individual words, though sometimes phrases or characters depending on the task. Once tokenized, Fast Stylometry employs a “bag of words” model, which disregards grammar and word order, reducing the text to a list of unique words and their frequencies. This reduction to word frequencies not only simplifies the data but also provides the foundation for further analysis.
The bag-of-words model used here is crucial for identifying stylometric features, as it enables the extraction of unique word patterns, authorial markers, and lexical frequencies that contribute to authorship attribution. Ignoring grammar and word order is advantageous in this context, as the focus is on stylistic elements, such as word choice and frequency, rather than meaning or syntax. By transforming the data in this way, the text becomes ripe for additional machine learning and NLP techniques, which rely on these vectorized representations to establish a structured dataset that computers can readily analyze for patterns and trends.
Fast Stylometry for Burrough’s Delta
John Burrows' Delta method is one of the leading stylometric techniques used for authorship attribution today. It calculates the “distance” between a text with unknown authorship and a corpus of texts by known authors, aiming to determine the closest stylistic match. Delta compares the anonymous text to multiple authors’ stylistic signatures simultaneously. Specifically, it measures how both the anonymous text and texts from various known authors deviate from the average of the entire corpus. By assigning equal weight to each feature it measures, the Delta Method mitigates the risk of common words skewing the results, working almost oppositely to visual tools like word clouds. Due to these qualities, Burrows’ Delta method is widely regarded as a robust solution for authorship attribution.
Fast Data Science (FDS) has developed a specialized forensic stylometry model, known as Fast Stylometry, that allows users to identify an author based on their distinctive stylistic and linguistic “fingerprint.” This model relies on forensic linguistics principles, where unique patterns in word choice, sentence structure, and syntax create a “fingerprint” that is difficult to replicate. Fast Stylometry is particularly effective when it has access to texts of at least a few thousand words, as larger samples provide a richer dataset for identifying these subtle but consistent stylistic markers.
John Burrows' Delta method is a prominent stylometric technique for authorship attribution, measuring the stylistic "distance" between an anonymous text and a corpus of known authors' works. By comparing deviations from the average style across multiple texts, it minimizes the influence of common words, making it a robust tool for identifying authorship. Fast Data Science has further advanced this field with Fast Stylometry, a model that uses forensic linguistics principles to analyze unique patterns in word choice, sentence structure, and syntax. Fast Stylometry is most effective with larger texts, as they provide a richer dataset for detecting distinctive stylistic markers.
VOCABULARY RANGE
Before calculating Burrow’s Delta and generating graphs and charts, determining the optimal vocabulary size to work with is essential for accurate and meaningful results. Vocabulary size here refers to the number of unique words, or tokens, considered in each text sample. This choice has a significant impact on the analysis, as too small a vocabulary may omit important stylistic markers, while too large a vocabulary can introduce noise, including rare or irrelevant words that do not contribute meaningfully to authorship attribution. By identifying the best vocabulary size, we can ensure that our analysis captures a representative sample of each author’s unique stylistic features—such as frequently used words, sentence structures, or lexical choices—while excluding extraneous data that could skew results.
Ultimately, selecting the right vocabulary size enhances the interpretability of the resulting visualizations, such as graphs and dendrograms, making patterns in authorship and stylistic differences clearer. This choice enables us to maintain focus on the core stylistic elements, ensuring that the Burrow’s Delta analysis is both precise and capable of capturing the nuances that differentiate one author’s work from another.
The optimal vocabulary size for Burrow’s Delta varies depending on factors like the text's length, genre, and language. Texts with dense, descriptive language might benefit from a larger vocabulary, while simpler, more repetitive texts might require fewer unique words to capture their essence. Experimentation is often needed to find the best balance, which can involve testing different vocabulary sizes and evaluating their impact on the accuracy and reliability of Burrow’s Delta calculations.
In the table below, you can see the experiments I did comparing a known text from each of the three potential authors to the larger training corpus to see what vocabulary size provided the most accurate results. In this specific set of calculations—executed using the function calculate_burrows_delta(train_corpus, test_corpus, vocab_size=25)—a lower Delta score indicated a closer match between the texts, thus representing higher accuracy in the results. Choisy’s Mémoires pour servir à l'histoire de Louis XIV is represented by “louisxiv,” Perrault’s La Belle au bois dormant by “belle,” and Madame L’Héritier’s Marmoisan or L’innocente tromperie by “marmoisan.” The result that is best for each author will have the cell(s) highlighted.
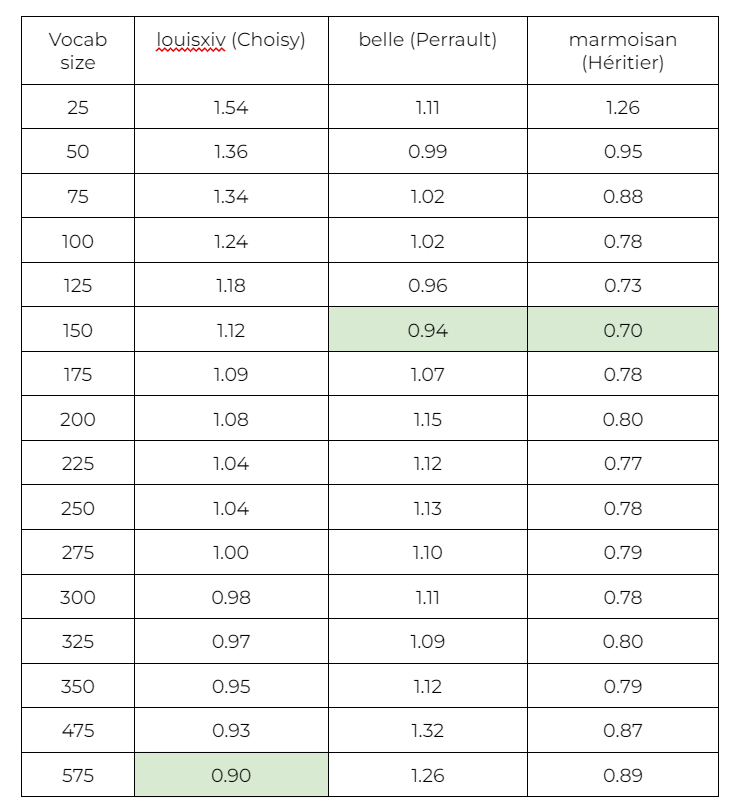
(Table 2. Known Author text compared to that same author’s larger corpus.)
The results are interesting and highlight that there are similarities in L’Héritier and Perrault’s frequency of word usage. The both showed the most accurate results with a vocabulary size of 150 words, making this their ideal size for Burrow’s Delta calculations. This means that for these authors, limiting the analysis to 150 unique words captured the essential stylistic elements needed for reliable attribution, without introducing excessive noise.
Choisy, however, proved to be an outlier. His ideal vocabulary size seems to be significantly larger, at 575 words, suggesting that a broader range of vocabulary better captures the unique stylistic traits in his writing. This difference may indicate that Choisy’s style is more complex or varied, requiring more lexical data for accurate analysis. This might also be a reflection of the diverse scope of Choisy's writing included in the corpus, which spans gossiping stories, pious histories, and travelogs. In contrast, L’Héritier and Perrault’s contributions to the corpus are more narrowly focused on fairy tales, a genre with its own characteristic simplicity and recurring themes. The broader vocabulary required for Choisy likely reflects his wider thematic range and more complex narrative style, underscoring how genre and content diversity can influence authorship attribution models.
The distinct vocabulary requirements across these authors underscore the importance of tailoring vocabulary size to each writer's unique style, as it enhances the precision of Burrow’s Delta in differentiating authors.
DELTA RESULTS
With the optimal vocabulary sizes established, we can now turn to the Delta Scores to observe how effectively these tailored parameters distinguish each author. The following section presents the calculated Delta Scores, illustrating the degree of stylistic similarity between each edition of the Histoire and the three potential authors (calculate_burrows_delta(train_corpus, test_corpus, vocab_size = 150).
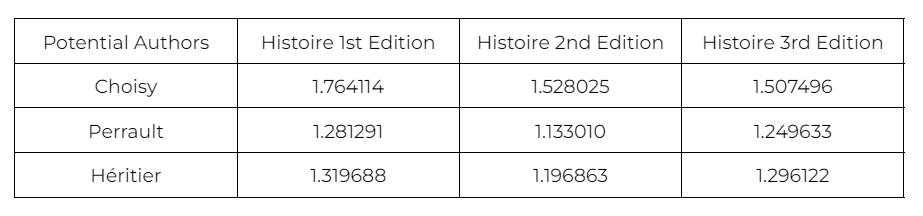
(Table 3. Burrows’s Delta Method applied to 150 size vocabulary.)
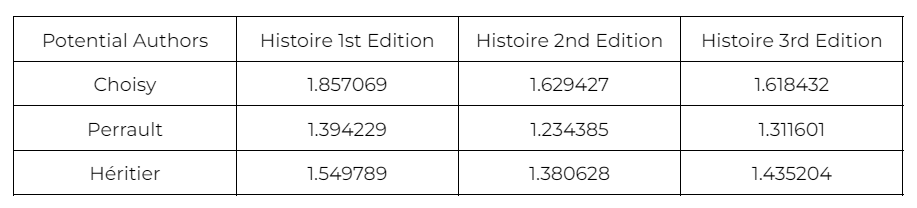
(Table 4. Burrows’s Delta Method applied to 575 size vocabulary.)
Although the 575-size vocabulary initially showed promise for Choisy, particularly in the exploratory phase, its performance didn’t yield any significant improvements when applied in the Burrows's Delta calculations for the Histoire texts. Interestingly, Choisy’s Delta scores at this larger vocabulary size did not display a notable decrease, and remained generally consistent across the different editions. This lack of improvement suggests that increasing the vocabulary size beyond 150 words doesn’t necessarily enhance the model’s accuracy or clarity when distinguishing between potential authors. As such, the larger vocabulary size was primarily included for comparison and exploratory purposes, providing insight into how varying the vocabulary affects attribution accuracy. Ultimately, the comparison highlighted that, while a broader vocabulary can sometimes help reveal nuanced stylistic elements, a carefully chosen smaller vocabulary may be more effective for the specific goal of authorship attribution.
If I were to approach this project again, I would aim to include a broader range of work styles by both Perrault and L’Héritier. Currently, the dataset relies heavily on fairy tales for these two authors, while Choisy’s contributions span a much wider thematic and stylistic range—from lighthearted gossip and travelogs to serious historical accounts. This difference in genre variety may skew the results in favor of Perrault and L’Héritier, as the algorithm’s focus on stylistic markers may overlook or downplay the stylistic variety present in Choisy’s work simply because it doesn’t have a comparable range for Perrault or L’Héritier. By expanding the selection to include more varied types of texts from each author, such as Perrault’s moral tales or any historical or epistolary writings by L’Héritier, the analysis would provide a more balanced comparison across authors, reducing genre-based biases.
A more varied corpus for all authors would also strengthen the algorithm’s ability to recognize broader stylistic patterns that aren’t tied exclusively to one genre. This would offer a more accurate and comprehensive view of each author's unique voice and enhance the model’s generalizability across different types of content. Adding this range would not only contribute to more robust authorship attribution but also yield insights into how each author adapted their style across genres, enriching our understanding of their literary contributions.
Findings & Charts
The results from Burrow’s Delta analysis reveal intriguing patterns in authorship attribution across the three editions of the Histoire. Our potential authors are Choisy, Perrault, and L’Héritier, with delta scores calculated for each. Choisy shows delta scores of 1.764114 for the first edition, 1.528025 for the second, and 1.507496 for the third. Perrault, meanwhile, has notably lower scores: 1.281291 for the first edition, 1.133010 for the second, and 1.249633 for the third. L’Héritier’s scores are similarly low, with 1.319688 for the first, 1.196863 for the second, and 1.296122 for the third edition. Lower delta scores indicate closer similarity in word usage and vocabulary to the Histoire editions, making L’Héritier and Perrault more likely candidates for authorship than Choisy.
Interestingly, the first edition of the Histoire consistently yields the highest delta scores for all three authors, suggesting it has fewer stylistic similarities with any of them compared to the later editions. This shift could be due to the fact that the text nearly doubled in length from the first to the second edition, expanding from 7,085 words to 13,374 words. The increase in length may have introduced new vocabulary and stylistic features that align more closely with Perrault and L’Héritier’s known writing styles, bringing down the delta scores for the later editions.
While Choisy’s scores are generally higher, indicating less similarity, The concern was that his results could be skewed due to the diversity in his writings, which include memoirs, historical accounts, and travel narratives rather than fairy tales. However, if Choisy’s genre truly influenced the results unfavorably, we might expect Perrault and L’Héritier’s scores to be nearly identical given their similar genre and familial connection. Yet, the delta scores for Perrault and L’Héritier differ slightly across the editions, implying that their styles are not as interchangeable as one might assume. This distinction provides a clearer case for why both Perrault and L’Héritier may share stylistic links with the Histoire—a factor that further strengthens the hypothesis of shared authorship or influence within their literary circle.
Taking another look at the results, this time presenting them in chart format for clearer, more immediate interpretation. While visualizing the data, we can more easily observe trends and differences in delta scores across authors and editions, which may reveal additional insights that are less obvious in the numerical format alone:
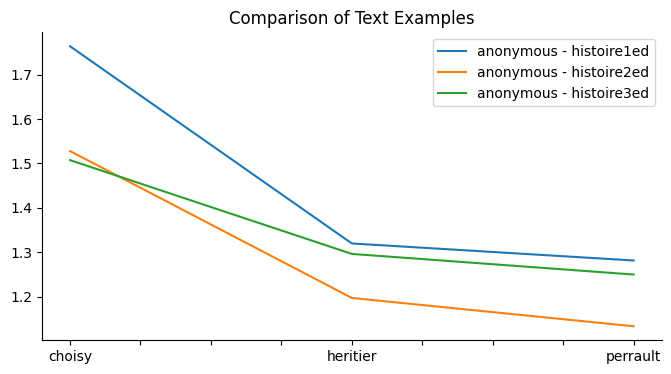
( Line chart created in Python.)
In reviewing the chart, it becomes strikingly clear that Perrault's writing style aligns most closely with the second and third editions of the Histoire de la Marquise-Marquis de Banneville. The modifications introduced in the third edition—such as added scenes and other content adjustments—seem to mirror Perrault’s stylistic tendencies even more closely. This suggests a potential editorial influence or at least a strong stylistic similarity, especially in the extended sections. However, the results are not as definitive as one might hope for in authorship attribution; the data leans toward Perrault and L’Héritier but does not entirely rule out other contributions or influences.
Interestingly, while the findings imply that Choisy likely wasn’t directly involved in the writing, this does not exclude the possibility of his influence through conceptual contributions, discussions, or even advisory input on the narrative. Choisy’s known association with the Histoire in certain historical circles might still indicate his influence on the text’s thematic or narrative elements, even if he was not the principal author. This opens an intriguing avenue for considering collaborative or dialogical influences on the work, which, while less visible through Burrow's Delta, might yet shape how the text was developed in its final form.
Conclusion
Queer narratives and identities are often viewed as recent constructs, but centuries-old myths and fairy tales reveal enduring themes of fluid gender, transformation, and self-discovery, connecting modern queerness to a deep-rooted storytelling tradition. Mythology, with its gods of shifting identities and transformative powers, flowed naturally into folk tales that retained these themes within human-centered narratives, reflecting societal values through familiar characters like tricksters and gender-fluid beings. As fairy tales evolved into a literary genre, they continued to address questions of identity, transformation, and belonging, often in subversive ways despite their moral closure and appeal to elite audiences. This connection between fairy tales and queerness, explored through the Histoire de la Marquise-Marquis de Banneville, inspired my research in Digital Humanities.
Leveraging tools like stylometry to analyze authorship, I sought to investigate whether computational techniques could resolve the question of the Histoire’s anonymous authorship, believed by some scholars to be linked to Perrault, L’Héritier, or Choisy. By applying programming skills and digital analysis to this obscure, distinctly queer tale, I aimed to bridge classic literature and modern technology, enriching both the understanding of the Histoire and the digital methodologies in literary studies.
When I first encountered the Histoire de la Marquise-Marquis de Banneville, it immediately resonated with me as a thesis topic for my Master’s in Rare Books and Digital Humanities. The story’s origins in the Mercure Galant, a 17th-century Parisian periodical influential among elite readers, particularly educated women, hinted at a unique social and literary context that engaged with gender and class norms. The Mercure Galant, founded by Donneau de Visé, showcased a diverse range of content, including poetry and social critiques, making it a cultural touchstone of late seventeenth-century France. The Histoire de la Marquise-Marquis de Banneville gained popularity, leading to reprints that reflected its significance. Inspired by this context, I adopted an interdisciplinary approach, combining rare book history with digital analysis to explore the story's history and scholarly reception. Through my research, I aimed to deepen the understanding of how stories with progressive themes circulated in early modern Europe, suggesting a more nuanced view of identity and narrative diversity than is often assumed.
The authorship of the Histoire de la Marquise-Marquis de Banneville has been attributed to three different individuals over the past three centuries, with significant scholarly discourse emerging primarily in the last century. In 1906, Paul Bonnefon proposed that the tale was likely written by Madame L’Héritier, a relative of Charles Perrault, rather than Perrault himself. Later, in 1928, Madame Jeanne Roche-Mazon suggested that the story might be a collaborative work between Perrault and the abbé de Choisy, adding complexity to the authorship debate. In 2004, the Modern Language Association published a standalone edition of the Histoire, which included an introduction by Joan DeJean that examined the potential authorship by considering various candidates, including the possibility of collaboration.
Despite the scholarly discussions, no definitive consensus has emerged, and notably, previous analyses have not utilized statistical or computational methods to explore these claims. This presents an opportunity for a new approach to authorship studies through modern text analysis techniques, aiming to uncover patterns that could clarify authorship and illuminate the broader context of gender and collaboration in late seventeenth-century literature. Ultimately, this research seeks to enhance the understanding of the Histoire's significance within the fairy tale canon and its place in literary queer history.
It’s true that determining authorship can resemble a literary mystery, requiring careful detective work to uncover the individual behind the words. Historically, authorship was less of a concern, with many ancient texts—like clay tablets and Greek philosophical scrolls—being circulated anonymously, as the focus remained on the content rather than the creator. It is only in recent centuries that authorship has gained importance, particularly with the rise of intellectual property and the celebration of the individual author. Today, while clear attribution is often expected, many works remain anonymous or pseudonymous, presenting challenges for scholars and historians. Establishing authorship typically relies on evidence and analysis; clear external evidence, like signatures, can confirm authorship, while contextual clues can help deduce the author in their absence.
In more ambiguous cases, quantitative analysis and stylometry—the statistical study of writing style—have become essential tools. This modern approach allows researchers to analyze texts for linguistic features such as word frequency and sentence structure, enabling comparisons to identify potential authors. By preparing and structuring data for stylometric analysis, I hoped to uncover patterns that could reveal the true authorship of the Histoire de la Marquise-Marquis de Banneville by examining texts from its three potential authors: de Choisy, Perrault, and L'Héritier.
My process of authorship attribution began with the selection and acquisition of texts related to the Histoire de la Marquise-Marquis de Banneville, focusing on early versions available at the BnF. These included both digital copies of first and second editions and a print version of the 1723 edition. After gathering texts from the three potential authors, my next step involved digitizing and preprocessing the data to ensure it was clean and uniform. This preprocessing entailed removing special characters and correcting any errors from OCR. The data was then structured using Python. The aim was to compare the linguistic styles of the Histoire with contemporaneous works by the three potential authors, ensuring a fair comparison based on themes, style, and historical context. Digital versions were sourced through the BnF's Gallica website the Internet Archive, and Project Gutenberg, while physical editions were captured using a scan tent for comprehensive analysis.
For the works that were not yet transcribed or accessible online, I used PDFs converted to PNG images and personal digital photos to create machine-readable texts via Transkribus and Tesseract OCR. Transkribus, known for its advanced transcription capabilities and user-friendly interface, was initially employed to transcribe L’Héritier’s Œuvres meslées and Choisy’s Journal du voyage de Siam. As I progressed in my studies, they gained familiarity with Python and utilized Tesseract OCR for processing the Histoire’s third edition images, finding it accurate for good-quality printed text.
I created a Python notebook for data processing and analysis using Google Colab for its integration with Google Drive, which simplifies data access and storage. I adapted data cleaning techniques from various online resources, employing NLTK for tasks like stop word removal and using the Fast Stylometry library for stylometric analysis, specifically Burrows’s Delta. The preprocessing involved removing common stop words and tokenizing the text, despite some redundancy, to maintain a smooth workflow. This text transformation, particularly through tokenization and the bag-of-words model, allows for effective analysis of stylistic features and authorial markers, setting the stage for further machine learning and natural language processing applications.
With the optimal vocabulary size established, my analysis shifted to the Delta scores, which assess how well these tailored parameters differentiate among the authors of the Histoire. The calculated Delta Scores reveal the degree of stylistic similarity between each edition of the Histoire and the potential authors, Choisy, Perrault, and Héritier, when applying a 150-word vocabulary size. The results indicate that increasing the vocabulary size beyond this does not enhance authorship attribution accuracy, suggesting that a carefully selected smaller vocabulary may be more effective for this specific task.
The results of Burrow’s Delta analysis reveal significant insights into authorship attribution for the three editions of the Histoire, focusing on potential authors Choisy, Perrault, and L’Héritier. Delta scores indicate that Perrault and L’Héritier exhibit notably closer stylistic alignment with the Histoire editions compared to Choisy. The first edition consistently shows the highest delta scores across all authors, implying fewer stylistic similarities, likely due to its shorter length compared to the later editions. This increase in length may have introduced new vocabulary and features that align more closely with the styles of Perrault and L’Héritier. Although Choisy’s higher scores suggest less similarity, they may be influenced by the diverse genres of his works, which include memoirs and travel narratives.
Interestingly, while Perrault and L’Héritier share similarities in genre, their differing delta scores indicate distinct stylistic traits. A line chart visualization further supports the findings, demonstrating that Perrault’s writing style closely aligns with the second and third editions, suggesting a possible editorial influence. Although the results lean toward Perrault and L’Héritier, they do not completely exclude the possibility of Choisy's influence, hinting at potential collaborative contributions to the text’s thematic elements.
In conclusion, my study of the Histoire de la Marquise-Marquis de Banneville combines computational methods with literary analysis to explore authorship in the context of early modern queer narratives. By examining delta scores from stylometric analysis, I found that Perrault and L’Héritier’s styles aligned more closely with the Histoire than Choisy’s, suggesting that either or both authors may have contributed to the text. Interestingly, the analysis reveals that the first edition is the least stylistically similar to all three potential authors, perhaps due to its shorter length, which lacks the expanded narrative features present in later editions. This suggests that the text may have undergone editorial modifications that reflected the stylistic preferences of its possible authors over time, particularly in the second and third editions.
This computational analysis method could serve as a powerful tool for scholars of queer texts, encouraging nuanced discussions around authorship and identity in historical literature. By making my code openly available on my website, I aim to enable other researchers to apply these techniques to a range of texts, opening new possibilities for examining themes of gender and transformation across literary history. I hope this will inspire a cascading effect, where each study contributes to a growing body of scholarship that reexamines classic works with a fresh lens. I'll be making the Python notebooks available to humanities scholars on my website, presented in the Digital Object chapter after this one.
Future research could delve deeper into genre-specific influences and expand the analysis to include a broader corpus of texts from other contemporaries of Perrault, L'Héritier, and Choisy, which might yield further insight into stylistic trends within this literary circle. Additionally, applying machine learning techniques to authorship attribution could offer new perspectives on subtle stylistic markers, enriching our understanding of anonymous and collaborative authorship in early literary works. Ultimately, this research illuminates the intricate relationship between narrative form and authorial influences in historical texts, showing the potential for digital humanities to enhance both literary scholarship and our understanding of early queer identities.